Generate domains with AI
Brandable DomainsAt Your Fingertips
A database of 1,294,245 available & brandable one-word domain names for your next startup idea
As seen on
How It Works
The secret sauce behind One Word Domains
Curate
We curate a database of brandable 27,625 English words, spanning categories like “adjectives”, “nouns”, “verbs”, etc.
good
thrive
love
lead
free
stellar
super
woo
oasis
enjoy
agile
solid
wise
success
hey
secure
freedom
master
pure
aim
fast
well
fun
happy
boom
excel
genius
liberty
easy
shine
ideal
best
bright
nice
glow
trust
uplift
hot
wow
great
awesome
zenith
brave
bravo
clarity
wonder
wisdom
joy
elite
smile
cool
inspire
savvy
creative
protect
fresh
welcome
royal
rapid
talent
fans
gold
gem
ready
authentic
bonus
brilliant
lucky
win
radiant
clean
nifty
perfect
skill
cozy
rich
accelerate
innovation
supreme
soft
beauty
support
bliss
unity
modern
fine
trusted
pride
smarter
grace
dynamic
lucid
trump
peace
noble
stable
boundless
right
breeze
harmony
paradise
fair
fortune
clever
sustainable
fidelity
like
peach
leads
aspire
fantastic
nimble
victory
calm
luxury
miracle
fame
fancy
intelligence
amazing
heal
lush
progress
audible
mighty
simplify
lean
strong
champion
luck
prosper
empower
ease
keen
fluent
autonomous
sharp
smooth
mastery
blossom
happiness
sparkle
faith
sexy
flourish
healthy
sustainability
pinnacle
revive
lively
treasure
cornerstone
valor
adaptive
fearless
premier
affinity
sweet
flutter
intelligent
crisp
patriot
positive
gain
golden
tender
zest
grand
cure
agility
glee
aplus
integral
wonderful
seamless
dawn
unlimited
optimal
affirm
posh
kudos
passion
majestic
loyal
sublime
vivid
charm
paramount
winner
marvel
classic
heaven
reward
neat
masterpiece
friendly
divine
luminous
advanced
merit
loyalty
revel
prestige
unbound
halcyon
unreal
poise
visionary
led
winning
beautiful
serenity
faster
recovery
vibrant
zeal
bullish
optimism
magical
winners
gems
holy
abundance
proper
yay
honor
incredible
handy
euphoria
remedy
works
shiny
destiny
brilliance
decent
promise
cute
speedy
prodigy
steady
heroes
pep
awe
humble
delight
honest
impress
carefree
chic
popular
comfort
comfy
respect
remarkable
hug
legendary
improve
advantage
envy
amaze
jolly
priceless
quiet
enhance
bless
foresight
excellence
goodwill
tidy
valiant
refresh
reform
masters
advocate
glory
slick
refine
regal
avid
illuminati
savings
empathy
renaissance
intuitive
breakthrough
precise
splendid
gratitude
superb
leverage
steadfast
reclaim
snappy
solace
profound
survival
nourish
brisk
cashback
inspiration
Crawl
We crawl various domain registrars to find the best prices for all 93 domain extensions (TLDs) in our database, among other stats.
.com domain names
Perfect for businesses of all sizes and industries. The .com TLD is the most trusted TLD worldwide, making it the go-to choice for companies looking to establish a strong online presence.
.io domain names
Perfect for innovative tech startups (I/O means input/output in computer science)- .io is a creative, and memorable TLD that helps companies to establish strong brand and succeed online.
.ai domain names
Perfect for companies working on artificial intelligence, machine learning, and other cutting-edge technologies. The .ai TLD offers a unique and attractive domain that is easy to share.
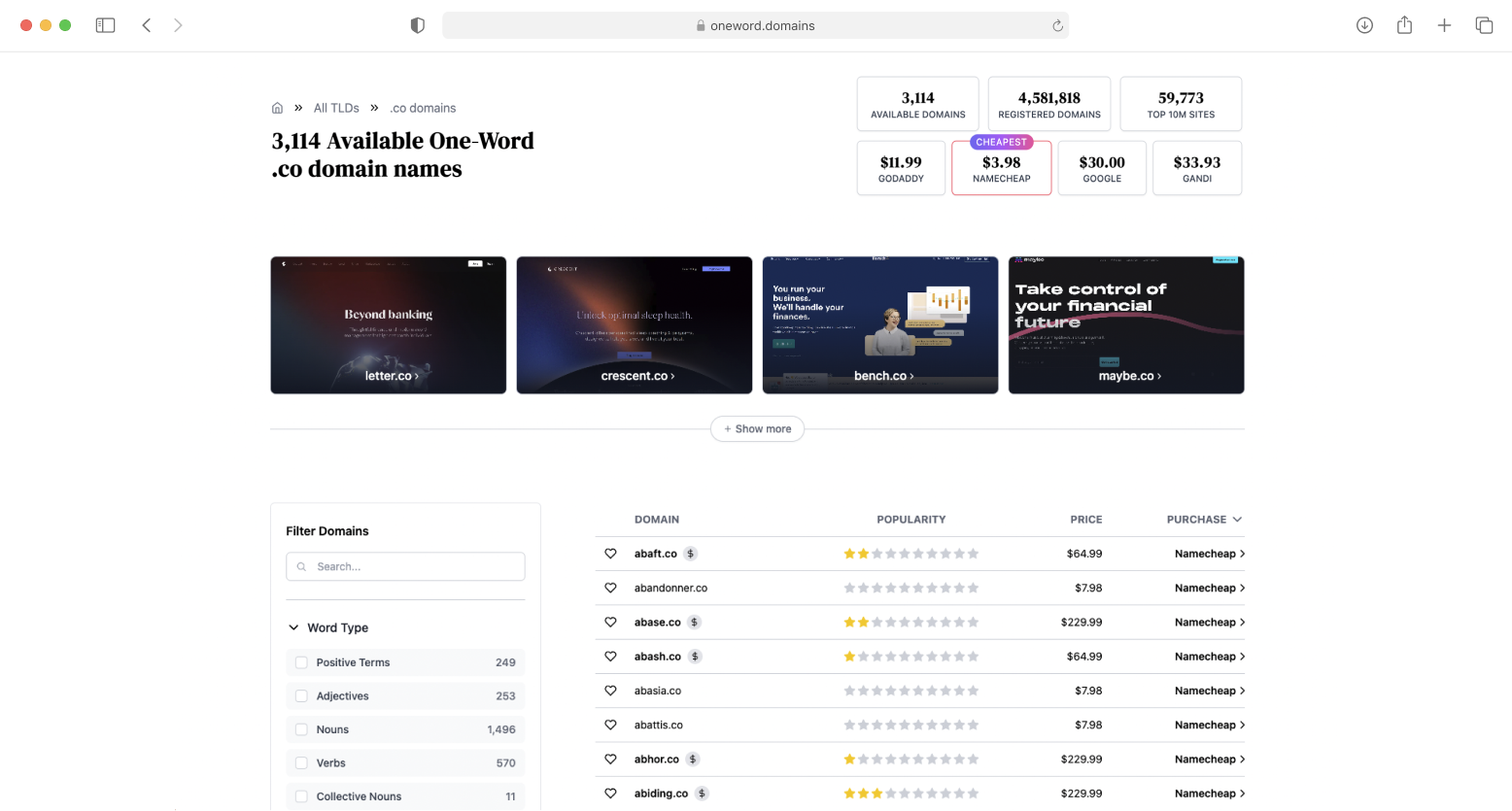
.co domain names
Perfect for startups and small businesses. The .co TLD is a memorable and professional TLD that tells customers you're a forward-thinking company ready to take on the competition."
.app domain names
Perfect for app developers and companies. The .app TLD is the ideal domain for showcasing and promoting your web, mobile, or other app-based business.
.com domains with -gpt suffix
Perfect for AI & GPT-related products. The .com domains with -gpt suffix is a popular domain style for companies building platforms revolving around AI & GPT-powered technologies.
.xyz domain names
Perfect for businesses in any industry. The .xyz TLD is a modern and creative TLD that tells customers you're forward-thinking and ready to take on the digital world.
.com domains with use- prefix
Perfect for companies that offer innovative products or services. The .com domains with use- prefix is a memorable TLD that tells customers to use what you offer to solve their problems.
.fyi domain names
Perfect for companies highlighted on the importance of sharing information. The .fyi TLD is a creative and brandable TLD that helps to establish credibility and trust with its customers.
.to domain names
Perfect for businesses and individuals. The .to TLD is a versatile option that helps to stand out online and improve search engine visibility.
Check
We run cron jobs every minute to check the availability status and price of all 2,569,125 domains in our database.
Recent Logs
Updates in real-time
gleefully.so became available
11s
11s ago
gleeful.so became available
2m
2m ago
sensilis.fi became available
4m
4m ago
separation.fi became available
4m
4m ago
serails.fi became available
4m
4m ago
sequella.fi became available
5m
5m ago
serapis.fi became available
6m
6m ago
separer.fi became available
6m
6m ago
sensitivity.fi became available
6m
6m ago
sentir.fi became unavailable
8m
8m ago
What People Are Saying
A list of testimonials from our satisfied customers
Simple no-tricks pricing
No monthly subscriptions, no hidden fees.
Lifetime Membership
Our lifetime membership gets you lifetime access to our database of over 1,294,245 available domains, plus any new content we add in the future for a simple one-time price.
What's included
Access to 1,294,245 domains over 93 TLDs
Filter and sort domains by popularity score
Unlimited access to future updates
2,000 Domains GPT credits
Pay once, own it forever
16 new users in the last 24h